Mathematical Properties of Deep Networks and Large Language Models
This page summarizes the mathematical counter-intuitive properties of over-parameterized systems, e.g., large language models (LLMs) among others, and explains the previous tendency for the use of increasingly large models. However, it seems that the emergence of DeepSeek-R1 (2025), a hybrid model combining both strengths of LLMs and reinforcement learning (RL), advocates the use of smaller models requiring less computer power and advanced processors.
The idea of representing complex data through an organized and hierarchical structure has been advocated by Herbert Simon (1962), a Turing Award and Nobel laureate, and a pioneer of artificial intelligence.
The design of these learning systems is influenced by inductive biases, thoroughly
presented in Goyal and Bengio (2022).
These connectionist systems are universal approximators, i.e., they can approximate any function $f(X)$:
$$
X \in \mathbb{R}^m\mapsto Y=f(X) \in \mathbb{R}^n, \: m, n \geqslant 1,
$$
and its derivatives.
The classical statistical theory of estimation is organized around the bias-variance trade-off. The overfitting of the function $f$, a small bias and a large variance, is avoided by using regularization methods, i.e., adding to the loss function $\mathcal{L}(Y,X;\theta) $ a weighted penalty term $\tau R(f)$, so that the estimation problem becomes:
$$
\min_{f \in \mathcal{H}} \mathcal{L}(Y,X;\theta) + \tau R(f),
$$
where $\mathcal{D}= \{X,Y\}$ is the dataset, $\mathcal{H}$ is the space of candidate functions, $\theta \in \Theta$ the set of hyperparameters to be estimated, $R(f)$ is a penalty functional with weight $\tau >0$. There is a wide literature on the selection of $\tau$, using either the Akaike or the Schwartz criteria, or adaptive methods.
The Double Descent : Interpolation Properties of Deep Networks
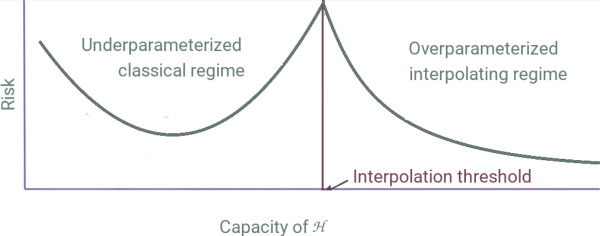
With the recent advent of deep learning and over-paramaterized systems, with up to a trillion of hyperparameters for the recent large language models (LLMs), it empirically appears that regularizing the loss function $\mathcal{L}(Y,X;\theta) $ is no longer an issue. This is the double-descent phenomenon, studied by Belkin et al. (2019, 2020) and Belkin (2021), and illustrated by the following generalization curve, which plots the risk versus the capacity of the space of candidate functions $\mathcal{H}$, such as its Vapnik-Chervonenkis dimension.
The trade-off between bias and variance in the classical case is graphically represented by the $U$-shaped curve in the left part of the graph, before the interpolation threshold. However, once the interpolation threshold is bypassed, the risk function decreases monotonically with the capacity of the over-parameterized system. The solution minimizing the loss function $\mathcal{L}(Y,X;\theta) $ maximizes the smoothness of the function subject to interpolating the data. The regularization is no longer necessary, one of the inductive biases is then removed.
Note that this empirical double-descent property has been formally demonstrated for the particular case of the
random Fourier features by Rahimi and Recht (2007): in the over-parameterized case, increasing the size number of parameters, i.e., the size of the neural network, entails that it converges to a kernel machine which minimizes the norm of the solution.
Landscape Topological Properties of Over-parameterized Systems
The landscape of the over-parameterized systems is neither convex, nor locally convex in a small neighborhood of a local minima.
However, topological properties, independently discovered by Łojasiewicz (1962) and Poljak (1963), and further studied by Liu, Zhu and Belkin (2022) entails both the existence of solutions and fast exponential convergence of the gradient descent (GD) algorithms, including the stochastic gradient descent (SGD).
The PL$^\star$ condition is defined as follows: a non-negative function $\mathcal{L}$ satisfies $\mu-$PL$^\star$ on a set $\mathcal{S} \subset \mathbb{R}^m$ for $\mu >0$ if
$$
\big \|\bigtriangledown\mathcal{L}(\theta) \big \|^2 \geqslant \mu \mathcal{L}(\theta), \quad \forall \theta \in \mathcal{S}.
$$
If $\mathcal{L}$ satisfies the $\mu-$PL$^\star$ condition in a ball of radius $O(1/\mu)$, then $\mathcal{L}$ has a global minimum in that ball. Furthermore, the (S)GD algorithm initialized at the center of such a ball converges exponentially to a global minimum of $\mathcal{L}$.
The condition PL$^\star$ has an analytic form via the spectrum of the tangent kernel, see Jacot et al. (2021). Over-parameterized systems, and then large neural networks satisfy PL$^\star$, while under-parameterized systems, i.e., the classical regime, do not verify PL$^\star$.
Belkin (2021) provides an exhaustive survey on the mathematical properties of the over-parameterized systems.
References
Belkin, M., 2021. Fit without fear: remarkable mathematical phenomena of deep learning through the prism of interpolation.
Acta Numerica 3, 203-248. MR4298218
Belkin , M., Hsu, D., Ma, S. and Mandal, S., 2019. Reconciling modern machine-learning practice and the classical bias-variance trade-off, Proc. Natl. Acad. Sci. USA 116, no. 32, 15849-15854.
MR3997901
Belkin, M., Hsu, D. and Xu, J., 2020. Two models of double descent for weak features,
SIAM Journal on Mathematics of Data Science 2, no. 4, 1167-1180.
MR4186534
DeepSeek-AI, 2025. DeepSeek-R1: Incentivizing reasoning capability in LLMs via
reinforcement learning.
arXiv preprint arXiv:2501.12948,
Goyal, A. and Bengio, Y., 2022. Inductive biases for deep learning of higher-level cognition.
Proc. R. Soc. A.478 no.2266, Paper No. 20210068, 35 pp.
MR4505795
Hinton, G., 2023. How to represent part-whole hierarchies in a neural network. Neural Computation, 35(3), pp.413-452.
MR4555492
Jacot, A., Gabriel, F. and Hongler, C., 2021.
Neural tangent kernel: convergence and generalization in neural networks (invited paper). STOC '21-Proceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing, 6. Association for Computing Machinery (ACM), New York,
MR43998812
Liu, C., Zhu, L. and Belkin, M., 2022. Loss landscapes and optimization in over-parameterized non-linear systems and neural networks, Applied and Computational Harmonic Analysis 59, 85-116.
MR4412181
Łojasiewicz, S., 1962. Une propriété topologique des sous-ensembles analytiques réels, in Les Équations aux Dérivées Partielles , 87-89.
MR0160856
Poljak, B. T., 1963. Gradient methods for minimizing functionals, Ž. Vyčisl. Mat i Mat. Fiz. 3, 643-653.
MR0158568
Rahimi, A. and Recht, B., 2007. Random features for large-scale kernel machines. Advances in neural information processing systems (NIPS 2007) 20 (J. C. Platt et al., eds), Curran Associates, pp. 1177-1184.
Simon, H. A., 1962. The architecture of complexity, Proceedings of The American Philosophical Society, 106(6), 467-482.
Jstor
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I. and Salakhutdinov, R., 2014. Dropout: a simple way to prevent neural networks from overfitting.Journal of Machine Learning Research 15(1), pp.1929-1958.
MR3231592
Teyssière, G., 2022. Review of "Belkin, M. (2021). Fit without fear: remarkable mathematical phenomena of deep learning through the prism of interpolation". Mathematical Reviews, American Mathematical Society.